After using NDepend (albeit rather episodically) for several years, I thought it would be only fair to talk about it, especially since static code analysis tools lately gained in importance and slowly but surely become standard part of development process. I came across the tool when I was doing active consulting work and at that time it was very helpful; so this somewhat informal survey will also repay its usefulness (since I used the free edition :).
For the purpose of this post I was using the version NDepend Professional 2.9.0 (thanks for the license to Patrick Smacchia).
The most interesting thing about NDepend is this: while most static code analysis tools for managed code (FxCop etc.) are used for identifying problems in code based on set of rigidly defined rules, NDepend takes altogether different approach. I am not even sure that NDepend should be called static code analysis tool – all right, it can be used for static code analysis in a manner similar to other tools, but it also has other uses that static code analysis tools lack.
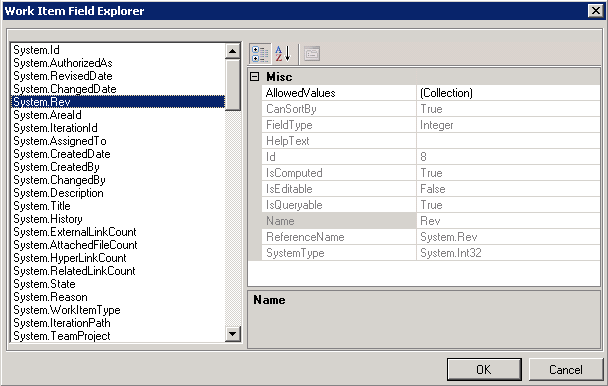
NDepend is all about analysis, and under “analysis” I mean looking at different levels of detail in your project: from class/method/line of code level (similar to most other tools), to assembly level to the project (set of related assemblies) level. Those different levels are easily accessible thanks to NDepend innovative UI techniques in presenting information as well as its original approach of defining rules. You see, NDepend does not have rules as they defined, say, in FxCop. Instead NDepend calculates set of metrics on compiled managed code, that can be aggregated in different ways, and provides Code Query Language (CQL) to query on metrics. Using metrics available and CQL, one gets high degree of flexibility with rules being defined as CQL queries. If you do not feel like authoring your own rules (or learning CQL), a decent set of pre-defined CQL queries is available out of the box.
To give an example of CQL-based rule (that serves the same purpose as FxCop rule CA1014 MarkAssembliesWithClsCompliant):
WARN IF Count > 0 IN SELECT ASSEMBLIES WHERE
!HasAttribute "OPTIONAL:System.CLSCompliantAttribute"
AND !IsFrameworkAssembly
Do you see the elegance of it? Not only the rule is readily modifiable, its definition is self-documenting (reading in pseudo-code “assembly is not attributed with ClsCompliant attribute and it is custom developed assembly”).
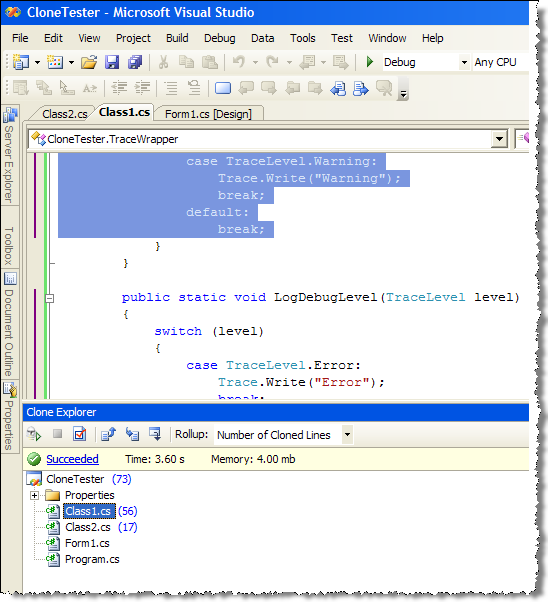
But that’s just one aspect of the tool – let me start with some screenshots to show off additional NDepend analysis capabilities.
Though NDepend provides command-line tool (as well as MSBuild tasks to run analysis as part of build script), you will want to use NDepend user interface, as it gives access to a lot of information in different cross-sections. UI is so flexible that some may say it is too flexible (meaning that one would need some time to get accustomed to NDepend UI and get the most of it).
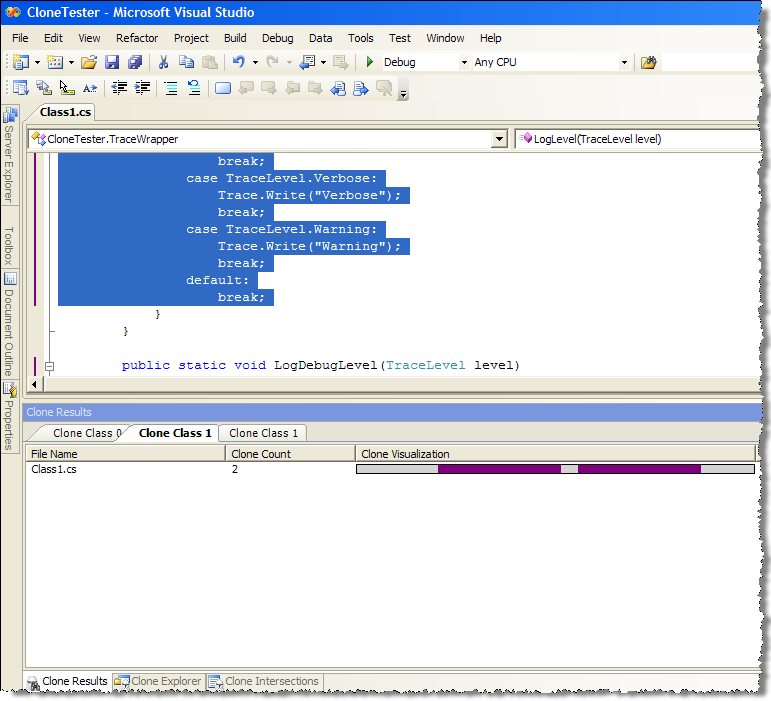
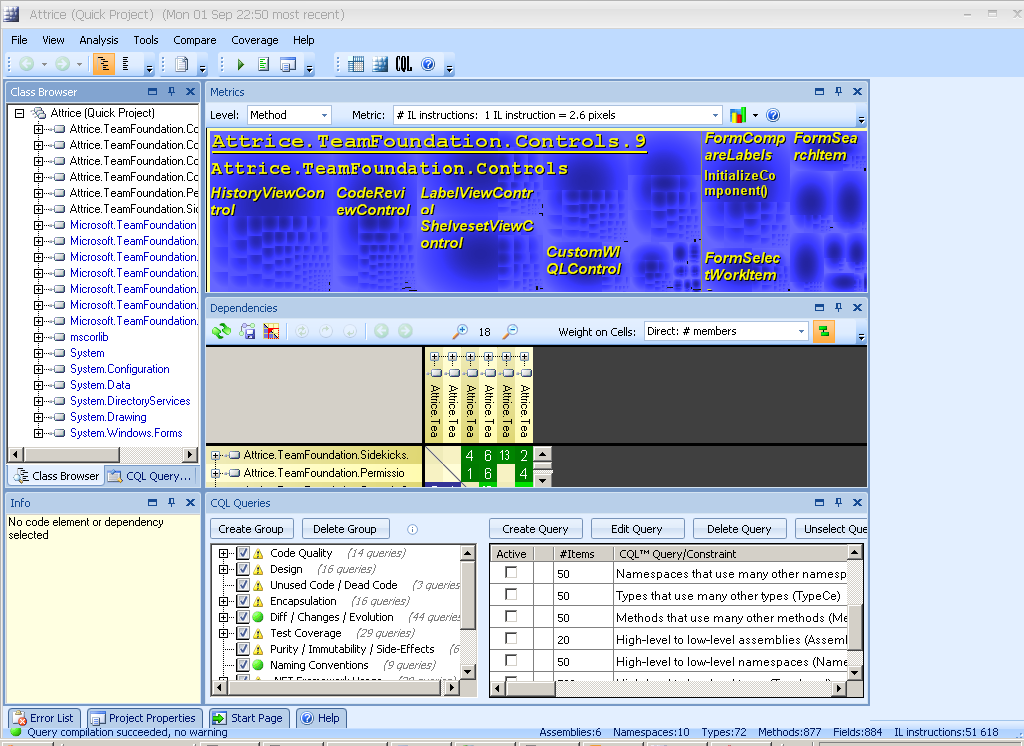
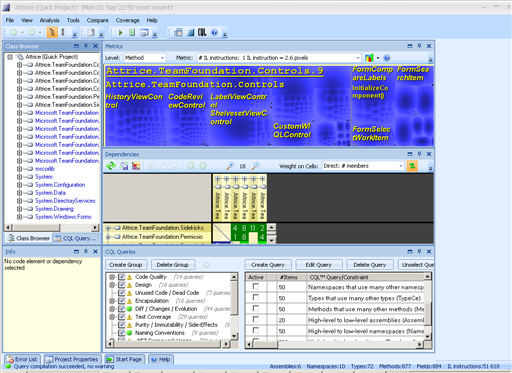
The awesome feature that was part of NDepend from its very beginning is “Metrics view”. As they say, picture is worth thousand words
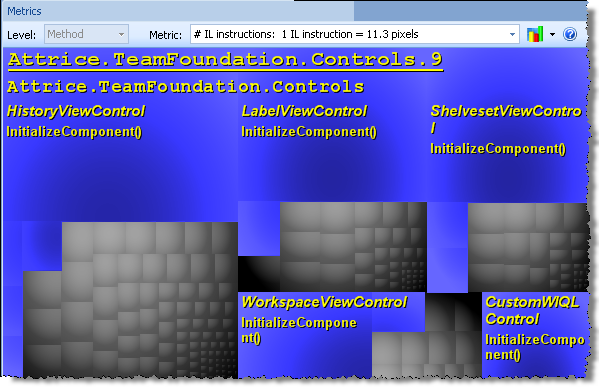
The largest rectangles correspond to assemblies, then assembly is made up of smaller rectangles corresponding to classes and finally every class is made up of rectangles corresponding to methods. The relative size of rectangles corresponds to calculated metric results for method/class/assembly. Metrics available range from simple ones (such as “number of IL instructions per method” or “Lines Of Code per method”) to calculated indexes (“Cyclomatic Complexity” or “Efferent Coupling”). When you mouse over the metrics map, the specific rectangles are highlighted and metric value for specific method is displayed.
This view is an awesome tool in itself, when you need to figure out the relative complexity of different classes, and especially so when dealing with unfamiliar code. You can use your favorite metric and immediately identify the most complex methods/classes by size.
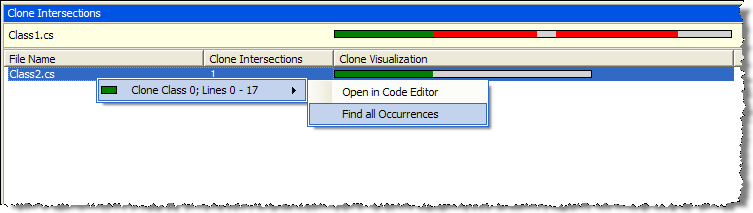
Other useful view is the “Dependency matrix”. When you need to analyze set of assemblies used in the same project, one of the important questions to answer is the dependencies between assemblies. Do the presentation assemblies access data access layer directly, and not through business logic? And if yes, what are the members that are responsible for those “shortcuts”? To answer this kind of questions, the dependency matrix view is invaluable:
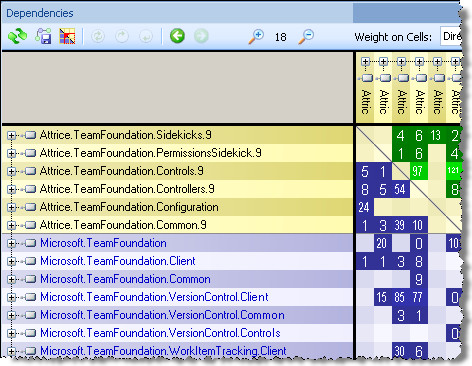
Note that the matrix above can be drilled down to namespace, classes and members level. Again, if you are trying to understand what are dependencies and dependents of certain assembly in a project, that’s the tool to use.
And now comes static code analysis part of tool. As I mentioned before, NDepend comes with set of predefined CQL queries that are roughly similar to, say, set of stock rules FxCop comes with. So you can run analysis on your assemblies right away using default rules.
Once you run analysis on your assemblies, NDepend will produce the detailed report (as HTML file) on your code that is not limited to rule violations (“CQL constraint violations” in NDepend terminology). In the report, you get to assess your code from different angles, and review the following:
- Assemblies metrics (# IL instructions, LOC etc.)
- Visual snapshot of code (same as available through “Metrics view”)
- Abstractness vs. Instability graph for assemblies
- Assemblies dependencies table and visual diagram
- CQL Queries and Constraints; that’s parallel to traditional “static code analysis violations” view. However, due to the nature of CQL, you get to see exact definition of every rule together with violations – to me that’s very sweet as in that way CQL rule is somewhat self-documenting
- Types metrics table that lists complexity rank, # IL instructions, LOC etc. in per method cross-section
However, you do not have to use the report – you may use UI to access the data in whatever way you desire. Two views that are of interest (in addition to previously mentioned “Metrics view” and “Dependency matrix”) are “CQL Queries” and “CQL Query Results”.
“CQL Queries” view is used to configure CQL queries to run during analysis (create/modify query groups, enable/disable specific queries or create/modify query contents)
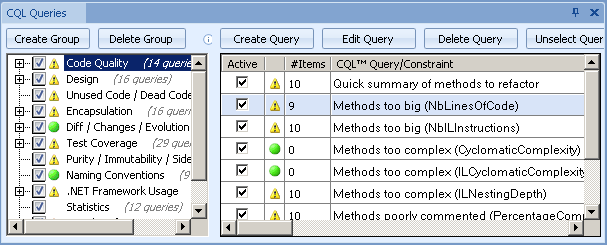
That’s where you can author your own rules or review the definitions of pre-defined rules (using dedicated “CQL Editor” window)
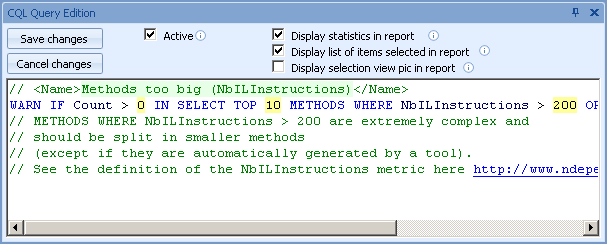
“CQL Query results” view is used to show selected query results (“rule violations” in context of static code analysis terminology)
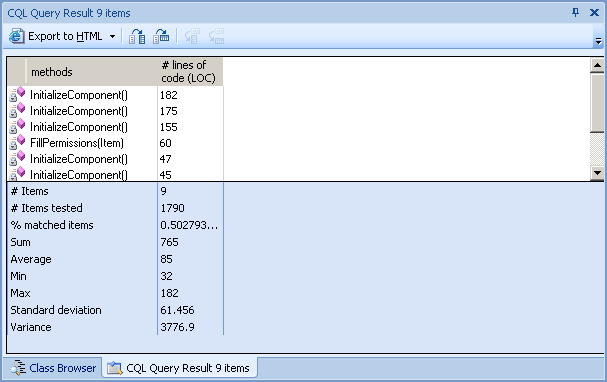
Note that there are statistics available for every CQL query that was run, that allow estimations against overall code base for that rule.
These two views provide all required functionality to access the results of analysis you have just performed. Myself, I use UI almost exclusively as for large projects the amount of data in HTML report may be overwhelming. However, the report will come in handy when you will have integrated NDepend into your automated build harness (and you can define custom XSL to fine tune report contents according to your needs)
Additionally, two features I wanted to mention is the ability to compare current analysis to historical analysis in the past (which is sadly lacking from most tools) and the availability of multiple flavors of NDepend application (console, stand-alone GUI, VS add-in, build tasks).
Now I’d like to give my personal opinion on when one would use NDepend over other alternatives.
NDepend may be your choice when
- You start working at large existing [managed] code base that is largely unfamiliar to you. NDepend is the tool to figure out the complexity of what you are dealing with, analyze the impact of changes in one component across the project and identify potential “roach nests”
- You are concerned with the quality of your code, and know exactly how to set up static code analysis for the project and what rules you’d like to have. Since all rules are based on human-readable query language, it is easy to figure out the rules meaning and to modify them/create new ones
- You and your fellow developers are technical savvy perfectionist bunch and like to fine tune your code and continuously improve it. NDepend is powerful tool with great many features, but you are ready to spend time on learning its capabilities and adjusting your processes (such as code review)
NDepend may be not as compelling when
- You (and your fellow developers) are new to static code analysis; moreover, implementing such practices has internal opponents in your company (that is, politics is a significant part of the process). In such case rich featureset may backfire; having a simpler tool such as FxCop would probably be easier to explain and integrate into the process.
- You do not have need in analyzing your application interdependencies and components; the only thing you need is static code analysis with limited set of rules
If you looking for resources on having a deeper look into NDepend, the best one to start with is NDepend official site. It has both bunch of online demos and traditional documentation as well.
Another resource that you might want to check out, is a blog of NDepend creator’s, Patrick Smacchia. If you ever doubted how powerful the tool is, the blog will disperse your doubts. By the way, make no mistake about it – his blog is an awesome read even if you do not care about NDepend, since Patrick tackles general issues of software development just as often.
Important side-note if you are looking to introduce NDepend at your company: NDepend is now a commercial tool, which is freely available for trial, educational and open source development purposes. Have a look at the comparison between Trial and Professional Editions (for commercial use you are looking at Professional Edition license, and for trial, well, Trial Edition).