While everyone else is blogging about VS 2010 Beta 2, I thought it still may be worth publishing this post that talks about VS 2008 behavior (yes, the old release ;).
One of the features missing in VS 2005 and added in VS 2008 was destroy command; people wanted to get rid of the source control artifacts for good and were unable to do so.
Interestingly, once the command become available it did not become too popular. Come think of it, there are very few cases where one can afford permanently deleting data; after all, source code is most valuable asset any software company has.
But should you decide on using destroy command, there are few important points to keep in mind:
1. Before executing destroy command, you might consider deleting item first. Leaving the item in “quarantine” while deleted for a week or so makes sure nobody uses the item (for example, as part of automated build) will miss it once it is completely gone. And once you are ready to delete it, use /preview switch to double check what files you are going to permanently wiped out
2. If you use destroy, destroy all versions of the item and do not fall for /keephistory option (with or without /stopat flag):
tf destroy $/Project/FolderOldName;C123 /stopat:C156 /keephistory
This option would destroy all (or some as in example above) versions of the item while retaining item’s history. It may be tempting to clean up database from old revisions leaving the history intact; the problem with this usage is that you will not be able to distinguish the revisions deleted when viewing the item’s history. That may lead to the following message when trying to view seemingly valid history:
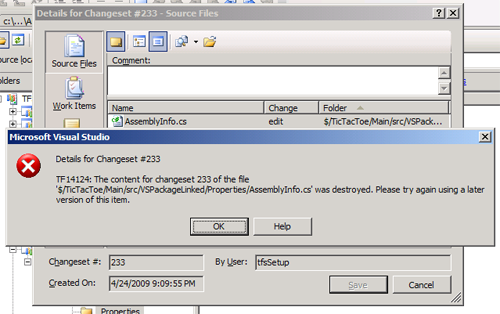
3. When you execute destroy command, data is not deleted from DB immediately. There is TFSVersionControl Administration job running on TFS Data Tier at scheduled interval that takes care of actual DB purging. You can trigger the job run immediately by using /startcleanup option (or running on SQL Server manually). The job does not take care of cleaning up the warehouse, it will get updated at warehouse processing scheduled intervals.
On a personal note, my usage of destroy was limited to removing sample & test TFS projects content; I never was able to get enough justification to permanently delete source code, however unused it may be. But your mileage may differ – if you do decide to get into destruction business, there are couple of very useful resources on TFS destroy that are not immediately discoverable through simple search; summary MSDN article and screencast How Do I: Use the TF Destroy Command in Visual Studio Team System 2008? by Richard Hundhausen.

