As I happen to write quite a lot about permissions lately, I thought I’d round it off with yet another post.
All permissions available in TFS (I do not take SharePoint or Reporting Services) fall in four categories
- Server global permissions
- Project global permissions
- Source control permissions
- Areas permissions
Certain principles apply to all categories, viz.
- Try to assign all permissions to TFS groups. That is, use TFS groups (server- or project-level) as containers to one or more Windows (AD domain or local) groups. That way the dependence on IT department is minimal, and it is easy to change the group membership while retaining overall permission structure
- Minimize permission assignments to users; try to use groups as much as possible. Only situations that are justified (in my opinion) are server/project administrators groups assignments. All other case should be groups. In this manner, you can maintain permissions on higher level (without figuring out how certain user is different from the rest)
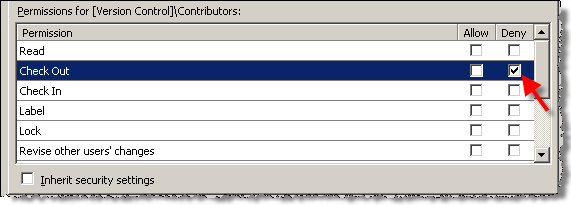
- Use Deny sparingly, since if the user is not admin and you deny access in one of his groups, it will not be easy to find which one
- Allow some time for permission assignment to get synchronized to the TFS database. Frequently, the users will want the permission to become effective there and then. But TFS has certain latency in updating the effective permissions, and if you plan permissions changes in advance you will avoid lots of time and prevent users frustration.
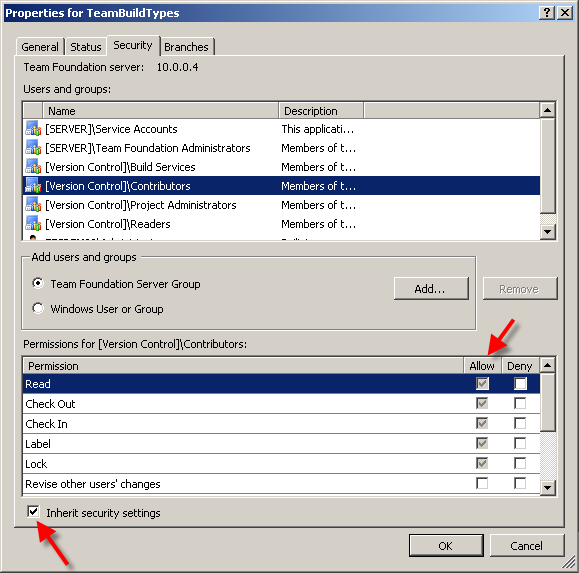
And now I would like to touch some version control specific permission issues (since this is by far most complicated topic, not in the least because inheritance is allowed in version control)
- Set as few permissions as possible. Ideally, you would set permissions on server, project and immediate project subfolders at most (and set server/project permissions by assignment to appropriate pre-defined groups). That way you will be able to immediately know where to look for the “root” of any permission problem.
- Never set permission on files (that can be viewed as more of the same topic as in previous paragraph, but I cannot say that enough).
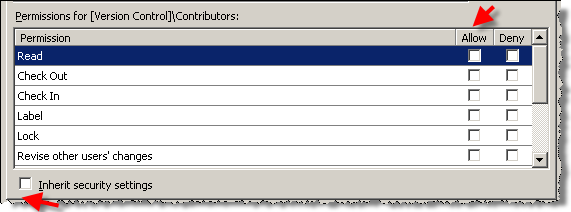
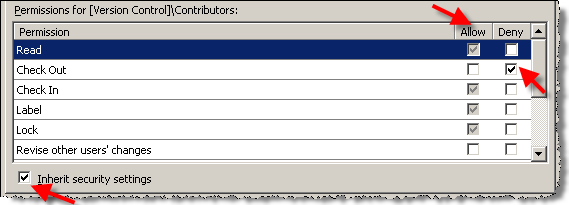
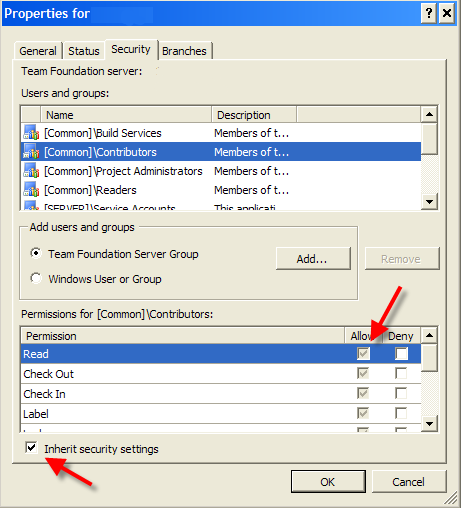
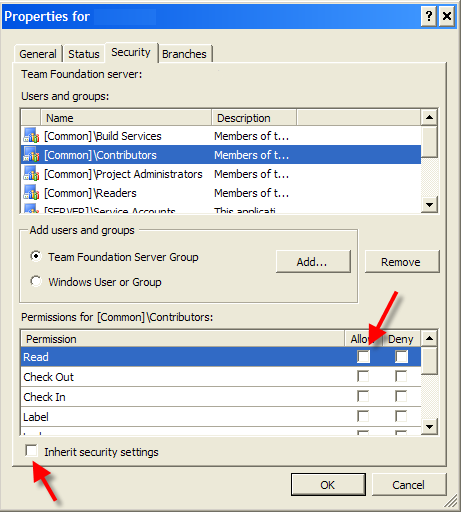
- Use inheritance as much as possible; start with most permissive set-up and partition by using Deny.
- If you find yourself setting certain permissions more than once, script them using tf permissions (use tfssecurity for global and area permissions). In this way potential for human error is minimized.
And to conclude, I would highly recommend not just set permissions ad hoc as you go along, but create some permission model (I know it sounds big, but Excel table that clearly delineates the common groups and permissions set may well be sufficient). If you are not sure – start with default groups and permissions, and assign your users appropriately to default groups. Believe me, that would be way better than creating complex permissions soup that your users swim in (and hate you all the while – and they will let you know their feelings).
By the way, you might want to watch Sidekicks blog for the soon-to-happen new release announcement (that will include Permission Sidekick). Stay tuned!
Related posts
When permission inheritance is a godsend
When permission inheritance is evil
Deny or allow – who wins? A sequel
Deny or allow – who wins?